You are right - it is not allowed YET.
So sponsors will probably continue to generate Suppqual datasets for some time, and also this is supported by SDS-XML, as SDS-XML can contain any tabular clinical data.
One of the major problems reviewers had is that when looking at a supplemental qualifier datapoint, it was (using the SASViewer) not easy to quickly find the record in the parent dataset.
So how does the "Smart SDS-XML Viewer" deal with this?
Below you find a few screenshots of the example files that came with the define.xml 2.0 specification (but now formatted as SDS-XML). It has 10 supplemental qualifier datasets, of which 3 are for the QS domain only (SUPPQSCG, SUPPQSCS and SUPPQSMM).

Let us now look at the SUPPAE dataset. For a good number of the subjects, it has one or more records.

So how can we now quickly see the parent record in the parent dataset?
The "Smart SDS-XML-Viewer" easily allows this using the menu "Tools - Show parent record of SUPPQUAL record". Just select a record (or single cell) in the SUPPAE table and then use that menu. A message shows up:


This can also easily be achieved using the keyboard shortcut CTRL-S ("S" standing for SUPPQUAL). One can then easily toggle between the SUPPAE table and the AE table either using the mouse and clicking the tab, or using the menu using "Tools - View - Last selected table", or even very simple using the keyboard shortcut CTRL-B ("B" for back). So using CTRL-B just toggles between the two tables.
The sample file also contains SUPPQUAL datasets for which the records do not point to an individual parent record, but to a set of records in the parent dataset. For example, the SUPPQSCG dataset for which IDVAR has the value "QSCAT", meaning e.g. for the first record that the supplemental qualifier refers to all records in the QS dataset for which QSCAT is "CORNELL SCALE FOR DEPRESSION IN DEMENTIA (CSDD)".

Selecting the fourth record and then using CTRL-S (or using the menu), then gives:
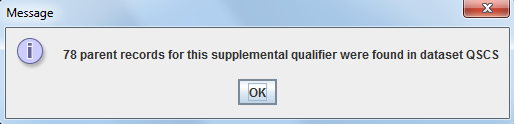
stating that there are 78 parent records, i.e. 78 records for that subject for which the QSCAT applied.
Hitting the OK button then brings us to the QS table and selects and highlights these 78 parent records:

Cool isn't it? Try to do this using the SASViewer ...







{kind=link}